02. Pretraining: What Actually Happens When You Train on 10,000 GPUs
TL;DR
Training a frontier model is no longer a modeling problem — it's a distributed systems problem. Think of it like running a single stateful application across 10,000 nodes that must stay perfectly synchronized, where any node can die every few hours, and the network is the bottleneck — not compute. The industry has evolved from simple replication to 4D sharding strategies, but the fundamental problems (fault tolerance, scheduling, utilization) are the same ones infra engineers have always faced — just at a scale where every known pattern breaks.
A note on how I organize these posts: Distributed systems have existed for decades. AI Infra hasn't. But the problems — fault tolerance, scheduling, network bottlenecks, straggler mitigation — are not new. They're showing up in a different form. Throughout this series, I use infrastructure analogies (databases, Kubernetes, networking, observability) to bridge the gap. If you've run large-scale infra, you already have the mental models. This is just a new application of them.
The Problem
If you've operated large distributed systems, this will sound familiar:
You have a workload that's too big for one machine. You need to spread it across thousands. But unlike a stateless web tier where you can scale horizontally and independently — this workload is one giant stateful computation where every node must stay in lockstep.
Imagine running a single database transaction across 10,000 nodes, where every node must agree on every intermediate step, and the transaction runs continuously for months. That's closer to what large-scale training looks like.
Three things make it brutally hard:
You can't just shard and forget. Unlike sharding a database by key range, a neural network's layers are deeply interdependent. Splitting the model requires continuous cross-node communication at every step — think of it like a microservices architecture where every service calls every other service on every single request.
The network is the bottleneck, not compute. GPUs are insanely fast at math. But synchronizing state across nodes is slow. It's like having a fleet of race cars stuck behind a single-lane bridge. At 10K GPUs, collective communication (the "bridge") can take longer than the computation it synchronizes.
Node failures are routine, not exceptional. If you run 10K GPUs, you expect hardware failures every few hours — the same MTBF math that drives SRE planning for large fleets. But unlike a stateless service where one dead pod is invisible behind a load balancer, one dead GPU in a synchronized training run halts everything.
The result: most large GPU clusters sit at 30-50% utilization. If that sounds like the old "we're paying for 3x the EC2 we actually use" problem — it is, except each GPU-hour costs $2-4 instead of $0.03.
The Strategy: How the Industry Got Here
Era 1: Data Parallelism — "Just add more replicas"
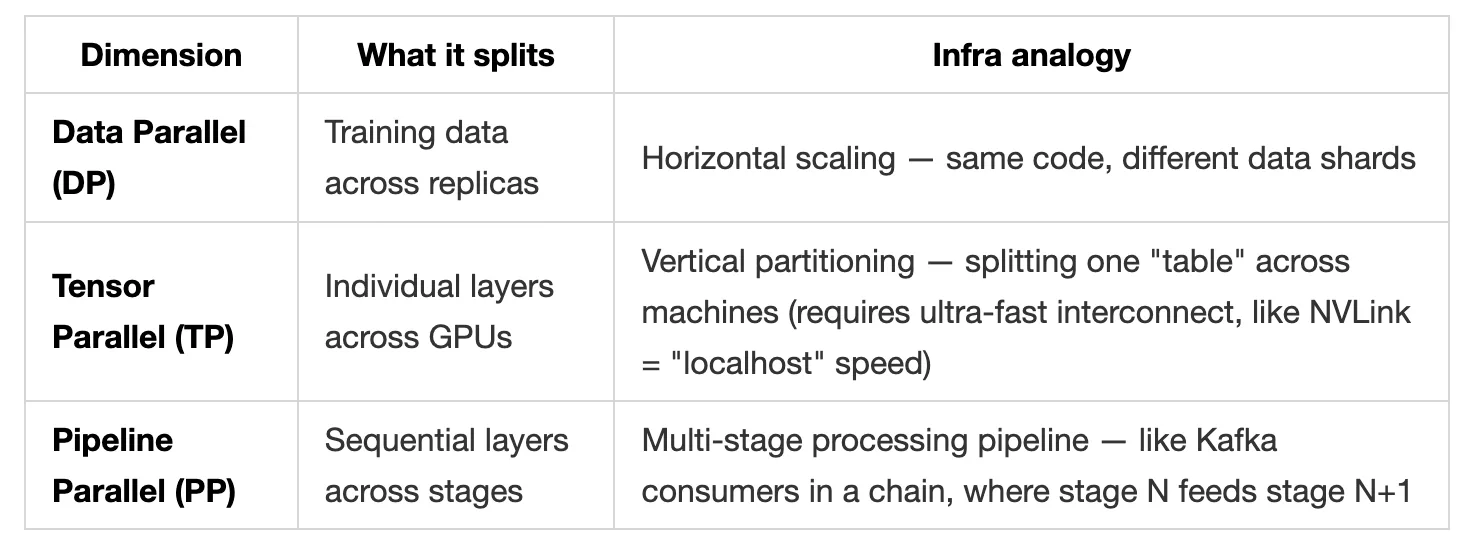
Infra analogy: This is like horizontal scaling with read replicas. Copy the full model to every GPU. Each GPU processes different data. Periodically sync state (gradients) across all replicas via all-reduce — similar to how distributed databases do quorum writes, except you're synchronizing on every single step.
Why it breaks: The model doesn't fit on one GPU anymore. A 70B parameter model needs ~140GB just for weights in BF16 — before optimizer states (another 2-3x). A single H100 has 80GB. It's like trying to run a 500GB database on a 80GB RAM instance. You must shard.
Era 2: 3D Parallelism — "Shard across multiple dimensions"
Infra analogy: Think of it like sharding a workload across three independent axes, similar to how you might partition a large system by geography (data parallel), by service function (tensor parallel), and by processing pipeline stage (pipeline parallel).
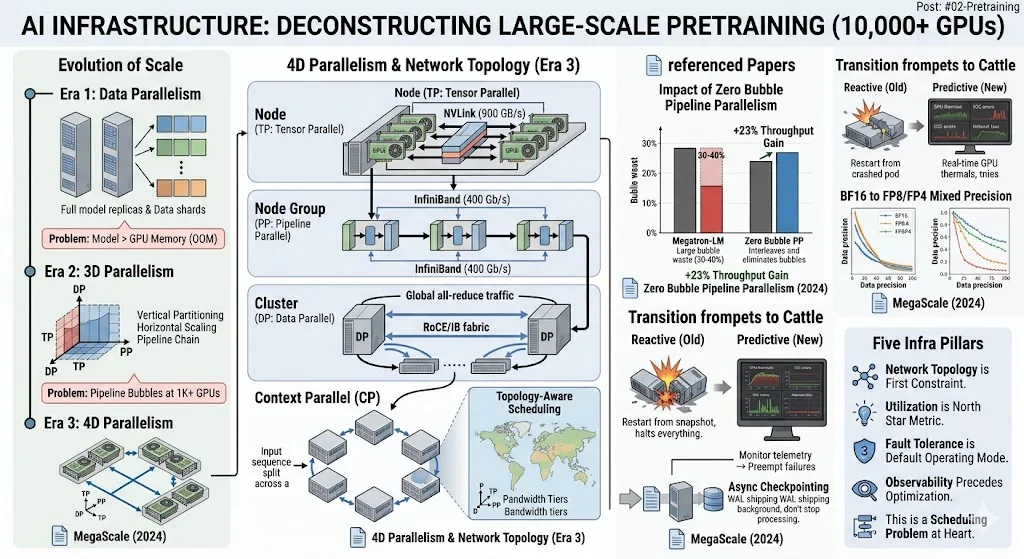
This works up to ~1,000 GPUs. Systems like Megatron-LM and DeepSpeed established this pattern.
Why it breaks at 10K+: Pipeline stages introduce bubbles — idle time while waiting for upstream stages. It's exactly like a multi-stage CI/CD pipeline where faster stages sit idle waiting for slower ones. At scale, these bubbles eat 20-40% of your GPU time. Meanwhile, all-reduce traffic across thousands of nodes saturates your network fabric.
Era 3: 4D Parallelism — "Respect the network topology"
Add a 4th dimension: Context Parallelism (CP) — splitting the input sequence itself across GPUs. Needed because 128K+ token sequences create activation memory that exceeds single-GPU capacity.
Infra analogy: This is like topology-aware scheduling in Kubernetes — but mandatory. The parallelism strategy must mirror the physical network hierarchy:
TP (Tensor Parallel) → within one node → NVLink (900 GB/s)
PP (Pipeline Parallel) → across nearby nodes → InfiniBand (400 Gb/s)
DP (Data Parallel) → across the cluster → RoCE / IB fabric
CP (Context Parallel) → across node groups → Ring-based communicationJust like you'd never schedule latency-sensitive pods across availability zones without thinking about network cost — you can't assign parallelism dimensions without respecting physical bandwidth tiers. Meta's Llama 3.1 and ByteDance's MegaScale both learned this the hard way.
The Technical Transformation
From "compute-bound" to "communication-bound"
Infra analogy: This is the same shift that happened when databases moved from disk I/O bottlenecked to network bottlenecked in distributed setups. The processing is fast — it's the coordination that kills you.
At 10K GPUs, a single all-reduce (synchronize gradients across all nodes) can take longer than the computation it synchronizes. The entire field of large-scale training optimization is now about hiding communication behind computation — the GPU equivalent of issuing prefetch requests while processing the current batch.
Key techniques:
Computation-communication overlap: Start sending gradients for layer N while computing layer N+1. Same principle as TCP pipelining or async I/O — don't wait for the ACK before sending the next packet.
Zero Bubble Pipeline Parallelism (2024): Splits the backward pass into two independent sub-computations and interleaves them like instruction pipelining in a CPU — filling every "bubble" with useful work. Up to 23% throughput gain.
FLUX (2024): Fuses communication and computation into single GPU kernels. Think of it like kernel bypass networking (DPDK) — eliminating the overhead of switching between compute and communication by doing both in one operation.
From "BF16 everywhere" to "FP8/FP4 mixed precision"
Infra analogy: This is compression for the GPU memory bus. Same principle as using smaller wire formats (protobuf vs. JSON) to reduce network bandwidth — except here you're reducing memory bandwidth by using fewer bits per number.
The transformation:
BF16 (current standard): 16 bits per value. Safe but memory-hungry.
FP8 (production today, H100+): 8 bits per value. ~39% memory reduction, ~75% faster. But the reduced dynamic range means you need per-tensor scaling factors — like auto-gain control on a microphone that adjusts in real-time to prevent clipping.
FP4 (experimental): 4 bits. 4x savings but maintaining numerical stability is like trying to run audio through a 4-bit DAC — technically possible, but the noise floor matters.
The infrastructure challenge: managing dynamic scaling factors across thousands of GPUs without introducing synchronization overhead. It's like running thousands of independently auto-tuning amplifiers that must still produce a coherent combined signal.
From "restart on failure" to "continuous fault tolerance"
Infra analogy: This is exactly the journey from "pets" to "cattle" — except harder, because in training, every "cow" carries unique state that can't just be recreated from scratch.
At small scale: GPU dies → restart from last checkpoint. Like restarting a crashed pod from a PVC snapshot. Annoying but fine.
At 10K+ GPUs: a node fails every few hours (same MTBF math as any large fleet). If each restart costs 10-30 minutes, you lose 10-20% of total compute to recovery overhead alone. It's like having a Kubernetes cluster where every pod crash forces a full rolling restart of the entire deployment.
The transformation:
Synchronous checkpointing → Async checkpointing: Write state to distributed storage without blocking training. Like WAL shipping in PostgreSQL — replicate state in the background, don't stop processing.
Full restart → In-place recovery: Hot-swap failed nodes without stopping the run. Like live migration in VMs, but for GPU memory and training state.
Reactive → Predictive: Monitor hardware telemetry (GPU thermals, ECC errors, network packet loss) to preempt failures. Same philosophy as predictive disk replacement in storage systems — replace the drive before it dies.
MegaScale's key insight: At this scale, observability is the prerequisite for everything else. They built distributed flight recorders that capture per-operator timing across 12K+ GPUs — the training equivalent of distributed tracing (Jaeger/Zipkin), but at microsecond granularity for every collective operation.
The Paper(s)
MegaScale (ByteDance, 2024)
What it solves: End-to-end production system for training 175B models on 12,288 GPUs.
Key insight: The bottleneck is never one component — it's the full-stack interaction between model parallelism, communication scheduling, data pipelines, network tuning, and diagnostics. Same lesson as microservices: system performance is dominated by the interactions, not the components. Achieved 55.2% MFU (1.34x over Megatron-LM).
Meta Llama 3.1 Training / TorchTitan (2025)
What it solves: 4D parallelism for 405B model training.
Key insight: Context Parallelism is necessary for long-context training. Communication topologies must match physical network layout — the same lesson we learned with rack-aware replica placement in HDFS and Cassandra.
Zero Bubble Pipeline Parallelism (2024)
What it solves: Pipeline bubble waste — idle GPUs waiting for upstream stages.
Key insight: Decompose the backward pass into independent sub-tasks and interleave them. Same principle as out-of-order execution in CPUs or work-stealing schedulers in thread pools. Eliminates bubbles entirely. +23% throughput.
Why This Matters for Production
If you're an infra engineer looking at pretraining infrastructure:
Network topology is your first constraint. Just like rack-aware scheduling in distributed storage — the parallelism strategy must respect physical bandwidth tiers. Ignore this and you'll hit 20% utilization.
Utilization is the North Star metric. The gap between peak FLOPs and actual MFU is your infrastructure tax. Think of it like CPU utilization for an EC2 fleet — except each idle percentage point costs 100x more.
Fault tolerance is the default operating mode, not an edge case. Design for continuous partial failure. If your system requires a clean restart on any node failure, you've already lost at scale.
Observability precedes optimization. You cannot tune what you cannot measure at per-operator, per-node granularity. Build the tracing/metrics first.
This is a scheduling problem at heart. Parallelism configuration, communication overlap, pipeline scheduling — it's all resource scheduling under constraints. If you've built job schedulers or worked on Borg/Kubernetes internals, the mental models transfer directly.
What's Still Unsolved
Transparent fault recovery without lost compute. No production system achieves live node replacement without pipeline stalls. It's the distributed training equivalent of zero-downtime deploys — everyone claims it, nobody fully has it.
Optimal parallelism auto-configuration. The 4D search space is enormous. Like auto-tuning database query plans, but with far higher dimensionality and the cost of a wrong choice is weeks of wasted compute.
Straggler diagnosis. A node running 5% slower is harder to find than a dead node. Partial NVLink degradation, thermal throttling, noisy-neighbor effects on shared switches — same class of problems as tail latency debugging in microservices, but with less mature tooling.
Checkpoint I/O bandwidth. Writing terabytes synchronously to distributed storage without blocking training. The filesystem/network can't keep up. Like trying to do a consistent database backup on a system doing millions of IOPS.
Training instability. Loss spikes at scale are common and poorly understood. DeepSeek-V3 claiming zero rollbacks across full training is noteworthy precisely because it's the exception.
References
MegaScale: Scaling Model Training to More Than 10,000 GPUs (ByteDance, 2024) — https://arxiv.org/abs/2402.15627
Zero Bubble Pipeline Parallelism (2024) — https://arxiv.org/abs/2401.10241
FLUX: Fast Software-based Communication Overlap on GPUs (2024) — https://arxiv.org/abs/2406.06858
FlashAttention-2 (Dao, 2023) — https://arxiv.org/abs/2307.08691
FP8-LM: Training FP8 Large Language Models (2023) — https://arxiv.org/abs/2310.18313
DeepSeek-V3 Technical Report (2024) — https://arxiv.org/abs/2412.19437
Meta Llama 3.1 Training Report (2024)
TorchTitan (Meta, 2025) — https://github.com/pytorch/torchtitan